Sentiment Analysis
Contents
This project is all about sentiment analysis as the title suggests. We are going to do so by using a state of the art model, called BERT (developed by Google).
We’ll start by installing amazing library, primarily applied in Natural Language Processing (NLP).
! pip install transformers
Importing some other packages and libraries:
import pandas as pd
import numpy as np
import requests
from bs4 import BeautifulSoup
import re
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
For our task we’ll use bert-base-multilingual-uncased-sentiment.
As stated in the official HuggingFace website:
This a bert-base-multilingual-uncased model finetuned for sentiment analysis on product reviews in six languages: English, Dutch, German, French, Spanish and Italian. It predicts the sentiment of the review as a number of stars (between 1 and 5).
model = AutoModelForSequenceClassification.from_pretrained('nlptown/bert-base-multilingual-uncased-sentiment')
tokenizer = AutoTokenizer.from_pretrained('nlptown/bert-base-multilingual-uncased-sentiment')
All our tokenizer will do is to convert a sentence to a sequence of numbers.
The function bellow is our main function in this code.
def sentiment_to_number(review):
tokens = tokenizer.encode(review, return_tensors='pt')
result = model(tokens)
return int(torch.argmax(result.logits))+1
How it works:
We will understand how it works with the help of an example:
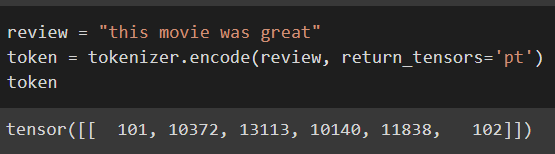
Step 1:
The tokenizer.encode returns a torch.Tensor object containing numbers that represents the given string.

Step 2:
Calling the model with the token from Step 1 will result in a SequenceClassifierOutput type object. The important part here is the tensor containing numbers which represents the probability of a particular class being the sentiment that corresponds the most to the review given.
Step 3:
torch.argmax will return the index of the biggest probability [0,4], than adding a 1 to it will give us a score between 1 to 5.
Scraping the data from ‘Rotten Tomatos’:
r = requests.get('https://www.rottentomatoes.com/m/the_lion_king_2019/reviews')
soup = BeautifulSoup(r.text, 'html.parser')
regex = re.compile('the_review')
results = soup.find_all('div', {'class':regex})
reviews = [result.text.strip() for result in results]
Creating pandas dataframe:
df = pd.DataFrame(np.array(reviews), columns=['review'])
Adding a score column for each review:
df['sentiment'] = df['review'].apply(lambda x: sentiment_score(x))
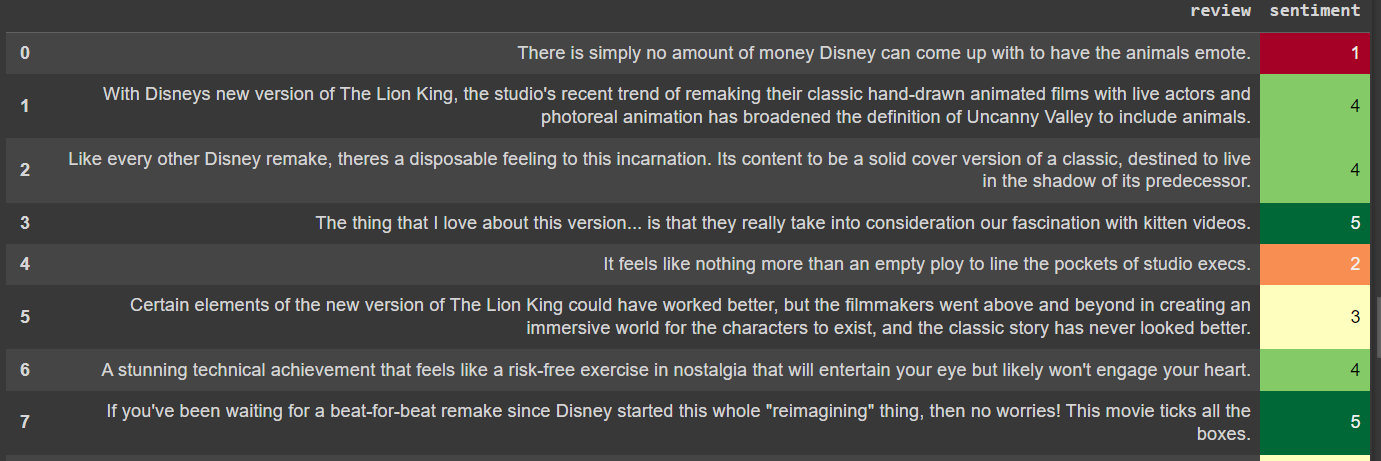
Another small trick we can use, adding background-color for the ‘sentiment’ column:
df.style.background_gradient(cmap='RdYlGn').set_properties(subset=['review'], **{'width': '300'})